
Arkville Agilex FPGAを用いたDPDKデータムーバー
BittWare WebinarArkville Intel® Agilex™ FPGA を使用した PCIe Gen4 Data Mover Webinar Atomic Rules 社のArkville IP は、最近更新され、Intel をサポートしました。Agilex


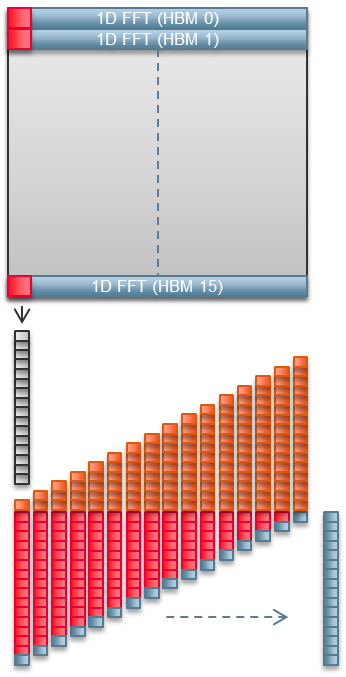
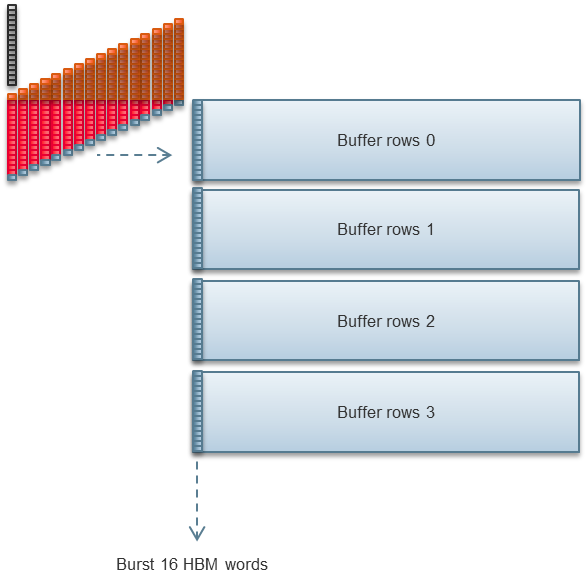
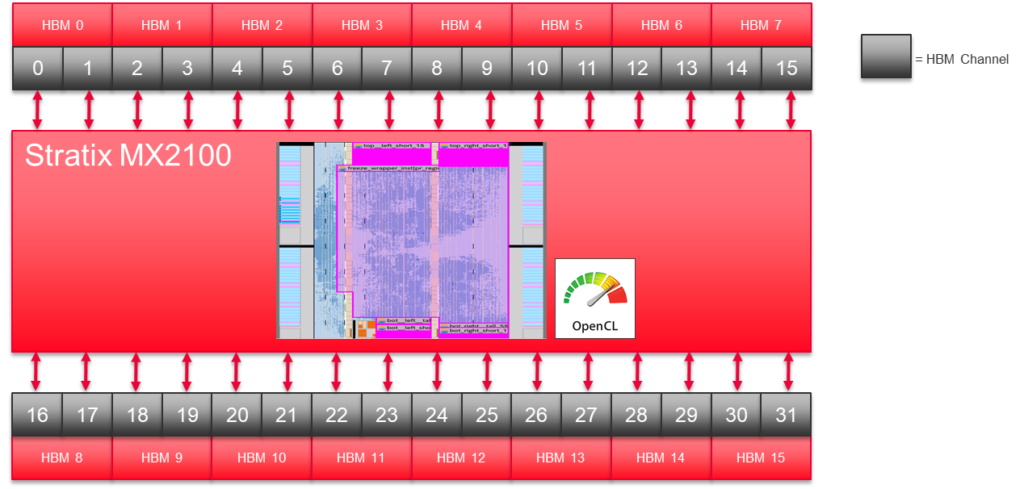 Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
BittWare WebinarArkville Intel® Agilex™ FPGA を使用した PCIe Gen4 Data Mover Webinar Atomic Rules 社のArkville IP は、最近更新され、Intel をサポートしました。Agilex

BittWare パートナーIPクエリプロセッシングユニット(QPU)構築FPGA搭載アクセラレータは、PCIe Gen4スピードで保存データまたはストリーミングデータを照会、分析または再フォーマットします!Eideticomのクエリ

BittWare パートナーIP TimeServo IPコア 高性能システムタイマIP Atomic Rules社のTimeServo IPコアは、RTL IPコアで、以下のような役割を果たします。

BittWare パートナーIP NVMeブリッジ・プラットフォーム NVMeインターセプト AXI-Stream サンドボックスIP 計算機型ストレージ・デバイス(CSD)は、ストレージ・エンドポイントに計算機型ストレージ機能(CSF)を提供することができます。