
웨비나 등록: 인텔 애자일렉스 FPGA를 사용한 컴퓨팅 스토리지 웨비나
인텔® 애자일렉스™ FPGA를 사용한 비트웨어 온디맨드 웨비나 컴퓨팅 스토리지: 데이터에 더 가까운 가속화를 가져오다 지금 온디맨드로 시청하세요! NVMe 스토리지를 가속화한다는 것은 다음과 같은 컴퓨팅을 이동한다는 것을 의미합니다.


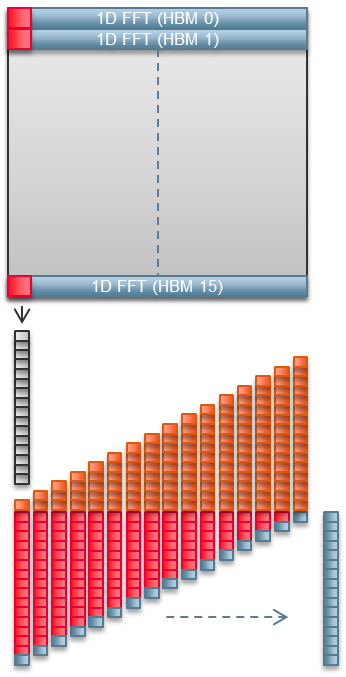
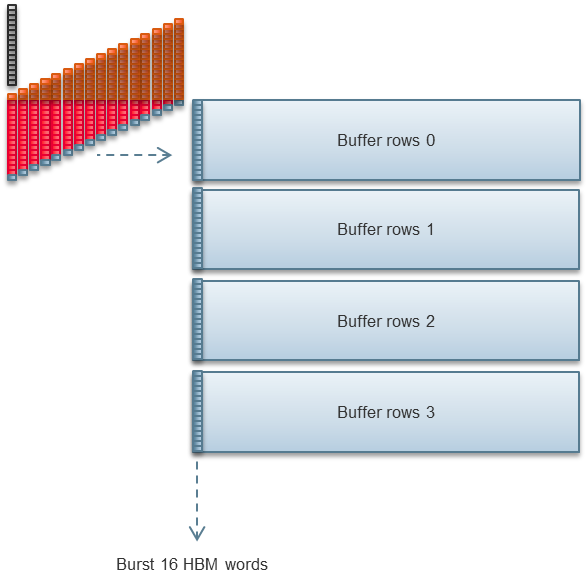
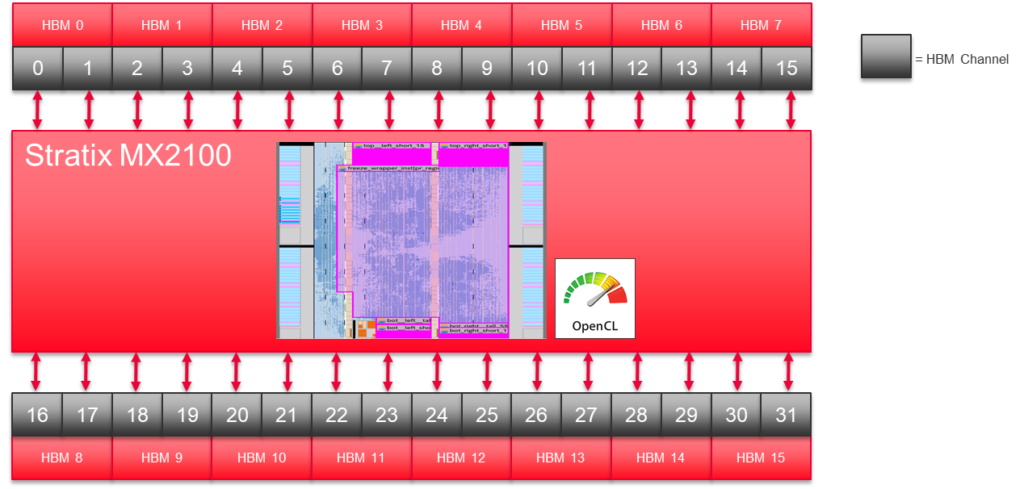 Stratix 10 MX에는 32개의 의사 HBM2 메모리 채널이 있습니다. 유니티의 2D FFT 구현은 이 채널의 절반을 사용합니다.
Stratix 10 MX에는 32개의 의사 HBM2 메모리 채널이 있습니다. 유니티의 2D FFT 구현은 이 채널의 절반을 사용합니다.
인텔® 애자일렉스™ FPGA를 사용한 비트웨어 온디맨드 웨비나 컴퓨팅 스토리지: 데이터에 더 가까운 가속화를 가져오다 지금 온디맨드로 시청하세요! NVMe 스토리지를 가속화한다는 것은 다음과 같은 컴퓨팅을 이동한다는 것을 의미합니다.
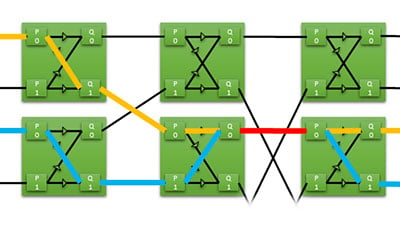
하나의 API에서 FPGA 리소스의 효율적인 공유 FPGA의 리소스 공유를 해결하기 위한 버터플라이 크로스바 스위치 구축 FPGA 카드의 리소스 공유 문제 FPGA 카드는 일반적으로 다음과 같습니다.


IP & 솔루션으로 돌아가기 UDP 오프로드 엔진 10/25/50/100GbE 아토믹 규칙을 위한 UDP 오프로드 엔진 UDP 오프로드 엔진(UOE)은 UDP FPGA IP입니다.