
网络研讨会注册:使用英特尔Agilex FPGA的计算存储网络研讨会
BittWare在线研讨会:使用Intel® Agilex™ FPGA的计算存储:让加速更贴近数据 现在按需观看!加速NVMe存储意味着移动计算,例如


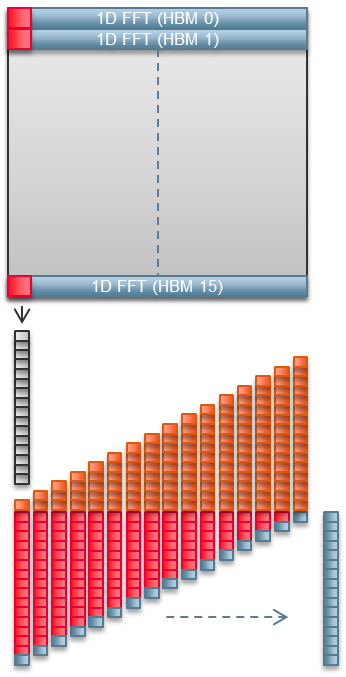
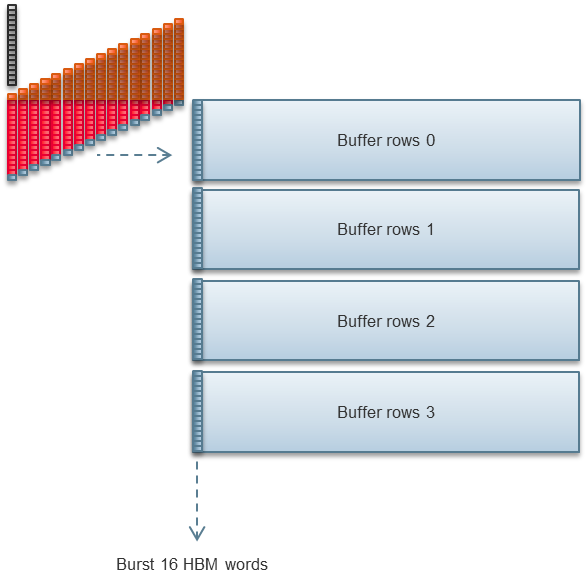
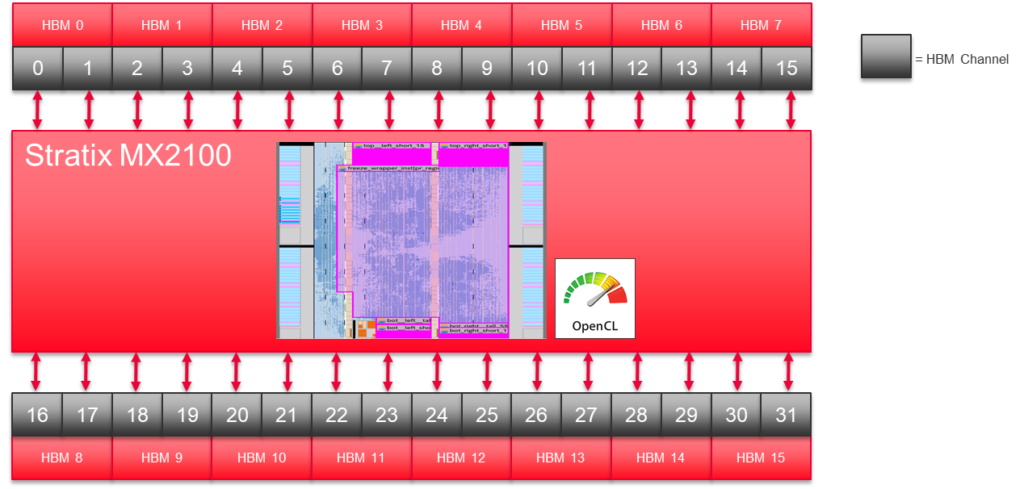 Stratix 10 MX有32个伪HBM2内存通道。我们的2D FFT实现使用这些通道的一半。
Stratix 10 MX有32个伪HBM2内存通道。我们的2D FFT实现使用这些通道的一半。
BittWare在线研讨会:使用Intel® Agilex™ FPGA的计算存储:让加速更贴近数据 现在按需观看!加速NVMe存储意味着移动计算,例如

BittWare网络研讨会采用下一代英特尔® Agilex™ FPGA的高性能计算,采用巴塞罗那超级计算中心的应用实例,现在可以点播(包括录制的内容)。
白皮书 BittWare的Loopback应用说明和实例简介 BittWare的Loopback实例演示了几件事:如何将Xilinx CMAC完全应用于

BittWare合作伙伴IP查询处理单元(QPU) 建立FPGA驱动的加速器,以PCIe Gen4的速度查询、分析或重新格式化存储或流式数据!Eideticom的查询